Thread
How does a neural network learn? 🔥
--A Thread--
🧵
--A Thread--
🧵
A neural network learns by evaluating predictions against the true values and adjusting the weights.
The goal is to obtain the weights that minimize the error, also known as the loss function or cost function.
The choice of a loss function, therefore, depends on the problem.
The goal is to obtain the weights that minimize the error, also known as the loss function or cost function.
The choice of a loss function, therefore, depends on the problem.
Classification tasks require classification loss functions, while regression problems require regression loss functions.
As the network learns, the loss functions should decrease.
As the network learns, the loss functions should decrease.
During the model training process, errors are reduced by the optimizer function.
This optimization is done via gradient descent. Gradient descent adjusts the errors by reducing the cost function.
This optimization is done via gradient descent. Gradient descent adjusts the errors by reducing the cost function.
Adjusting the error is done by computing where the error is at its minimum, commonly known as the local minimum.
You can think of this as descending on a slope where the goal is to get to the bottom of the hill, that is, the global minimum.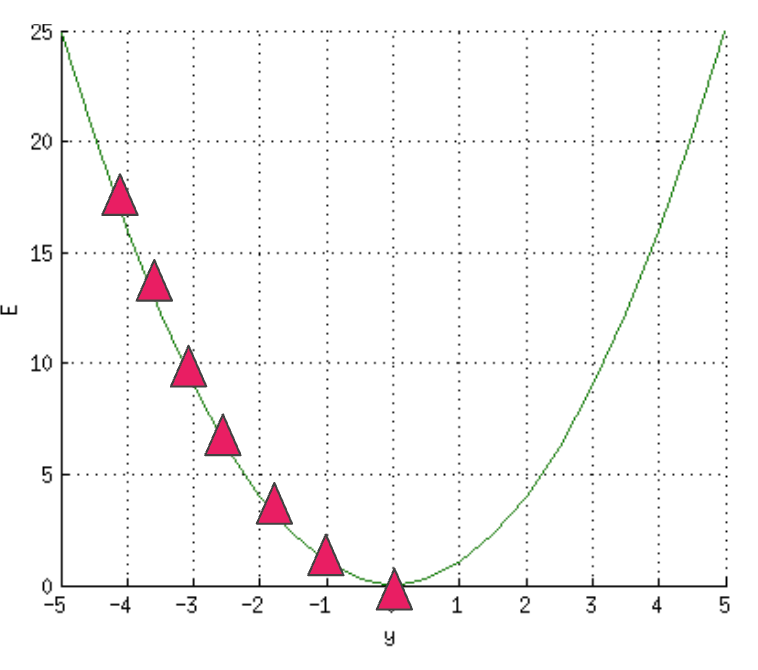
You can think of this as descending on a slope where the goal is to get to the bottom of the hill, that is, the global minimum.

The process involves computing the slope of a specific point on the "hill" via differentiation.
The computed errors are passed to the network, and the weights are adjusted. This process is known as backpropagation.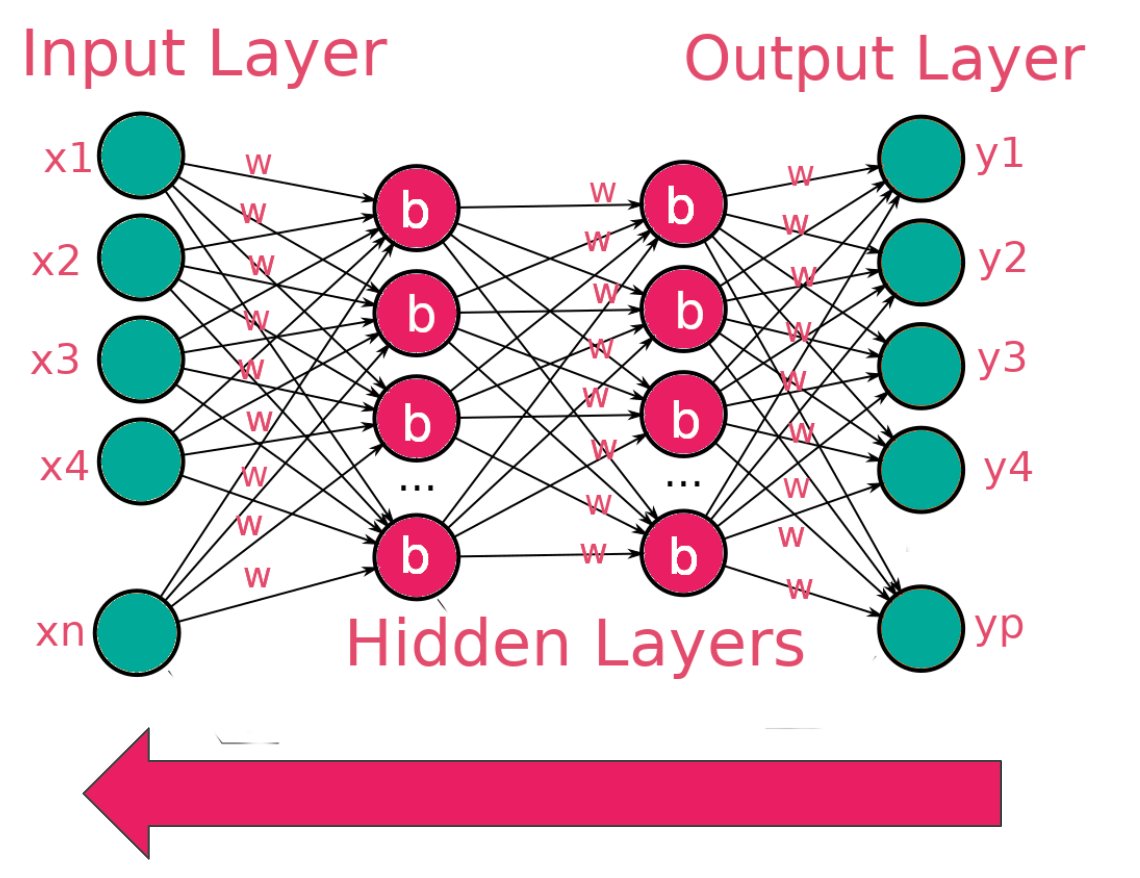
The computed errors are passed to the network, and the weights are adjusted. This process is known as backpropagation.

Variants of gradient descent include:
• Batch Gradient Descent uses the entire dataset to compute the gradient
• Stochastic Gradient Descent computes gradient from a single training example in every iteration.
• Mini-Batch Gradient Descent uses a data sample
• Batch Gradient Descent uses the entire dataset to compute the gradient
• Stochastic Gradient Descent computes gradient from a single training example in every iteration.
• Mini-Batch Gradient Descent uses a data sample
That's it for today.
Follow @themwiti for mere content on machine learning and deep learning.
Retweet the first tweet to reach more people.
Follow @themwiti for mere content on machine learning and deep learning.
Retweet the first tweet to reach more people.
Mentions
See All
RS Punia🐍 @CodingMantras
·
Mar 16, 2023
Great share! nicely explained...