Thread
ChatGPT is the most powerful conversational AI in the world.
It has 175 billion parameters.
GPT-4 is estimated to have 100 trillion.
Here’s what parameters mean and why you must understand them: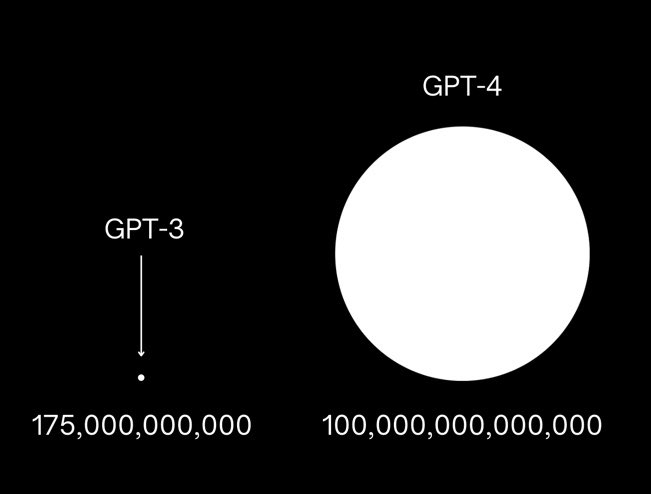
It has 175 billion parameters.
GPT-4 is estimated to have 100 trillion.
Here’s what parameters mean and why you must understand them:

1/ A simple analogy to explain what a parameter is
Imagine you're baking a cake.
The recipe provides you with a set of instructions.
• How much flour
• How much sugar and milk
• How many eggs
These ingredients and their quantities are the data used to train the model.
Imagine you're baking a cake.
The recipe provides you with a set of instructions.
• How much flour
• How much sugar and milk
• How many eggs
These ingredients and their quantities are the data used to train the model.
But you might need to make adjustments to the recipe to bake your perfect cake.
• Adjust the oven temperature
• Change the baking time
• Add more sugar
These adjustments you make to the recipe are like the parameters in a machine learning algorithm.
• Adjust the oven temperature
• Change the baking time
• Add more sugar
These adjustments you make to the recipe are like the parameters in a machine learning algorithm.
Put simply:
• The recipe is the algorithm
• The recipe adjustments are the parameters
It's how you turn the 'knobs' or 'dials' to tweak how the model behaves.
Because we all want to bake the perfect cake (or improve the model's performance).
• The recipe is the algorithm
• The recipe adjustments are the parameters
It's how you turn the 'knobs' or 'dials' to tweak how the model behaves.
Because we all want to bake the perfect cake (or improve the model's performance).
2/ Too many vs too few parameters
A model's performance is often evaluated based on its ability to make accurate predictions on unseen data.
Think of unseen data as a new chocolate cake recipe handed to you by a friend that you've never seen before.
A model's performance is often evaluated based on its ability to make accurate predictions on unseen data.
Think of unseen data as a new chocolate cake recipe handed to you by a friend that you've never seen before.
You use your previous experience to adapt to the new recipe.
More parameters can allow a model to capture more patterns.
But too many can be a problem.
Just like if you play with the dials too much.
The oven becomes too hot.
You risk burning the cake.
More parameters can allow a model to capture more patterns.
But too many can be a problem.
Just like if you play with the dials too much.
The oven becomes too hot.
You risk burning the cake.
3/ Overfitting vs underfitting
Overfitting happens when the model becomes too complex and is trained too much on the training data.
If a model is trained heavily on legal documents it may become too specialized in legal jargon and struggle to generate text on sports or fashion.
Overfitting happens when the model becomes too complex and is trained too much on the training data.
If a model is trained heavily on legal documents it may become too specialized in legal jargon and struggle to generate text on sports or fashion.
If you use too much data you might get mixed signals about what makes a good cake.
The results may not be reliable.
On the other hand, you might underfit the data.
Underfitting happens when the model is not trained enough resulting in it not capturing the patterns in the data.
The results may not be reliable.
On the other hand, you might underfit the data.
Underfitting happens when the model is not trained enough resulting in it not capturing the patterns in the data.
This makes it unable to generalise to new, unseen data.
In the case of our cake-baking analogy, underfitting could happen if you only bake one or two cakes.
If you have too little data you might miss important insights that could lead to baking better cakes.
In the case of our cake-baking analogy, underfitting could happen if you only bake one or two cakes.
If you have too little data you might miss important insights that could lead to baking better cakes.
You need to find the right balance between overfitting and underfitting to achieve the best possible result.
You need to bake enough cakes to capture patterns about what makes a delicious cake.
Without overdoing it & getting lost in the weeds by adding that extra gram of sugar.
You need to bake enough cakes to capture patterns about what makes a delicious cake.
Without overdoing it & getting lost in the weeds by adding that extra gram of sugar.
4/ Current trends
Models are getting smaller.
GPT-3 was 175B parameters.
InstructGPT was 1.3B parameters.
Eventually, you’ll be able to chop and change language models down to just a few hundred million parameters.
Models are getting smaller.
GPT-3 was 175B parameters.
InstructGPT was 1.3B parameters.
Eventually, you’ll be able to chop and change language models down to just a few hundred million parameters.
This will enable us to have models on the edge as @EMostaque puts it.
Removing the boundaries between humans and computers.
Your model will have your own knowledge.
You'll create your own world.
Each of our worlds/models will interact with one another.
Removing the boundaries between humans and computers.
Your model will have your own knowledge.
You'll create your own world.
Each of our worlds/models will interact with one another.
So what's the core takeaway?
Bigger models do not necessarily mean better outcomes.
It’s about having better data which leads to better outcomes.
Fine-tuning with human feedback helps align language models with human intent.
Bigger models do not necessarily mean better outcomes.
It’s about having better data which leads to better outcomes.
Fine-tuning with human feedback helps align language models with human intent.
We'll dive into reinforcement learning from human feedback (RLHF) next week.
Follow me @thealexbanks for more on startups and AI.
If you liked this thread, you'll love the newsletter.
Subscribe here:
noise.beehiiv.com/subscribe
Follow me @thealexbanks for more on startups and AI.
If you liked this thread, you'll love the newsletter.
Subscribe here:
noise.beehiiv.com/subscribe
Help everyone learn and retweet this thread:
Mentions
There are no mentions of this content so far.