Thread
You use CPUs and GPUs to deploy ML models every day.
But have you ever considered how they work in machine learning?
Here's how they differ and why you should choose a CPU over a GPU for your next deployment.
--A Thread--
🧵
But have you ever considered how they work in machine learning?
Here's how they differ and why you should choose a CPU over a GPU for your next deployment.
--A Thread--
🧵

1/ GPUs are loved for training and deploying ML models because they can bring data in and out quickly.
GPUs are built to perform a lot of compute to little data, not little compute to a lot of data.
GPUs run networks faster using more FLOPs.
GPUs are built to perform a lot of compute to little data, not little compute to a lot of data.
GPUs run networks faster using more FLOPs.
2/ Since GPUs have a small memory size, running large models through them requires grouping multiple GPUs and distributing the compute across them.
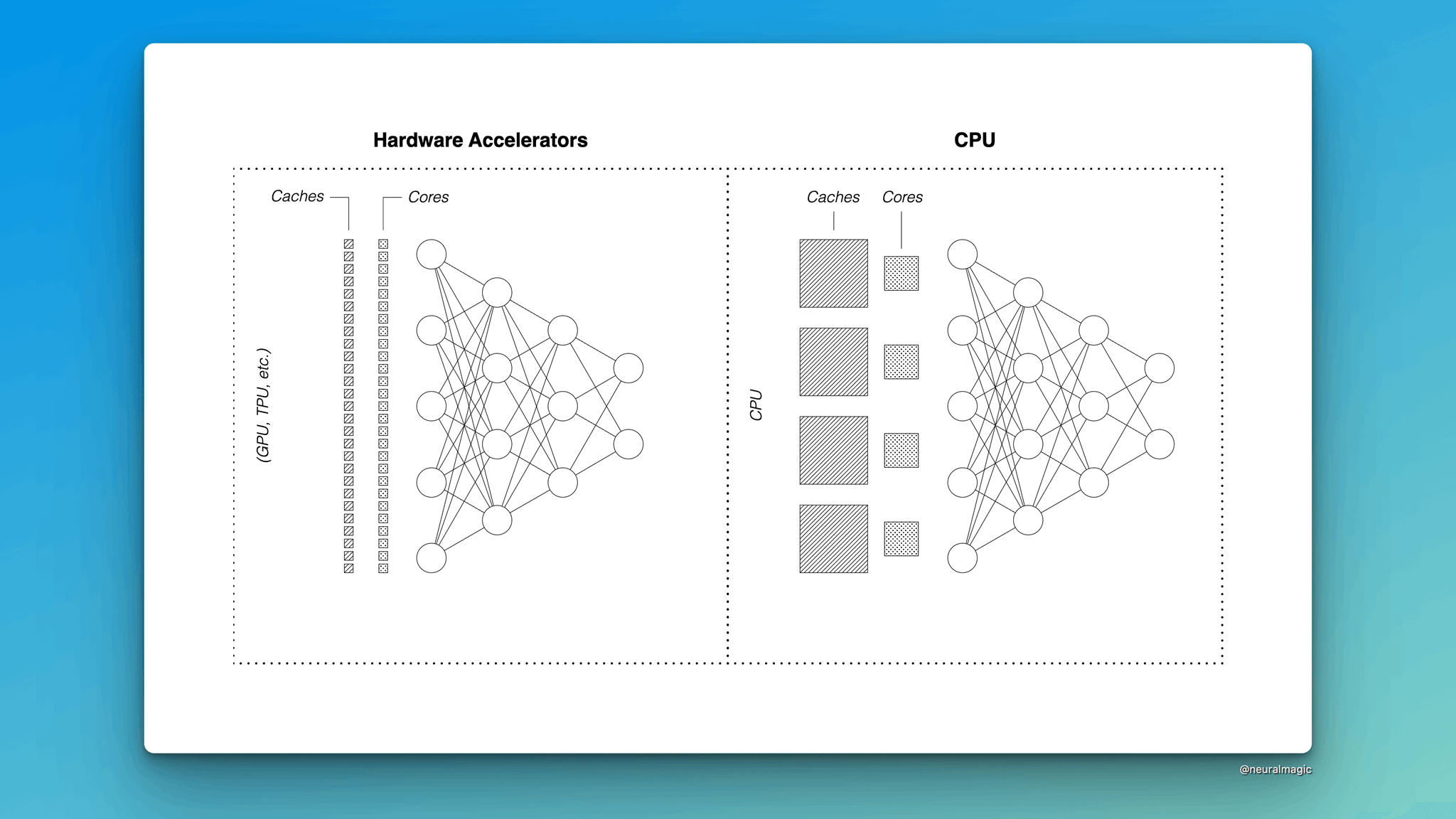
3/ CPUs have larger and faster caches than GPUs and have more memory.
These GPUs perform layer-after-layer execution using their thousands of tiny synchronous cores fully across each layer.
Unfortunately, the same doesn't work for CPUs because they have less overall compute.
These GPUs perform layer-after-layer execution using their thousands of tiny synchronous cores fully across each layer.
Unfortunately, the same doesn't work for CPUs because they have less overall compute.
4/ CPUs have powerful asynchronous cores with larger and much faster caches.
Hence, by reducing the number of FLOPs required, you can run a network faster on CPUs than on GPUs.
Reduction of the FLOPs is done by introducing sparsity in the network.
Hence, by reducing the number of FLOPs required, you can run a network faster on CPUs than on GPUs.
Reduction of the FLOPs is done by introducing sparsity in the network.
5/ Sparsification is done by removing unnecessary weights in an overparameterized network.
Sparsity can be achieved by using already sparse models by downloading them from SparseZoo or by using SparseML to fine-tune or train a sparse model.
Sparsity can be achieved by using already sparse models by downloading them from SparseZoo or by using SparseML to fine-tune or train a sparse model.
TL;DR
GPUs use more FLOPs to run networks faster. You can achieve GPU performance on CPUs by reducing the number of FLOPs. Done by sparsifying the network.
Once the need for more FLOPs has been reduced, you will need an inference runtime that can take advantage of sparsity.
GPUs use more FLOPs to run networks faster. You can achieve GPU performance on CPUs by reducing the number of FLOPs. Done by sparsifying the network.
Once the need for more FLOPs has been reduced, you will need an inference runtime that can take advantage of sparsity.
DeepSparse is an inference runtime that guarantees GPU-class performance on CPUs.
Are you interested in deploying ML on CPUs while achieving the same performance as expensive GPUs?
Join like-minded ML practitioners in our community to learn more.
join.slack.com/t/discuss-neuralmagic/shared_invite/zt-q1a1cnvo-YBoICSIw3L1dmQpjBeDurQ
Are you interested in deploying ML on CPUs while achieving the same performance as expensive GPUs?
Join like-minded ML practitioners in our community to learn more.
join.slack.com/t/discuss-neuralmagic/shared_invite/zt-q1a1cnvo-YBoICSIw3L1dmQpjBeDurQ
Follow @themwiti for more threads on machine learning and deep learning.
Mentions
See All
RS Punia🐍 @CodingMantras
·
Mar 11, 2023
Excellent thread!