Thread by Shayne Longpre
- Tweet
- Feb 27, 2023
- #ArtificialIntelligence #Deeplearning
Thread
🔭 A 🧵 on @OpenAI LLM "Alignment" (e.g. #ChatGPT)
Q: How does this differ from publicly available "Instruction Tuning" (IT)?
A: Proprietary Alignment is actually 3 separate components:
1⃣ Instruction tuning
2⃣ ➕ Open-ended generation/creative prompts
3⃣ ➕ Human feedback
1/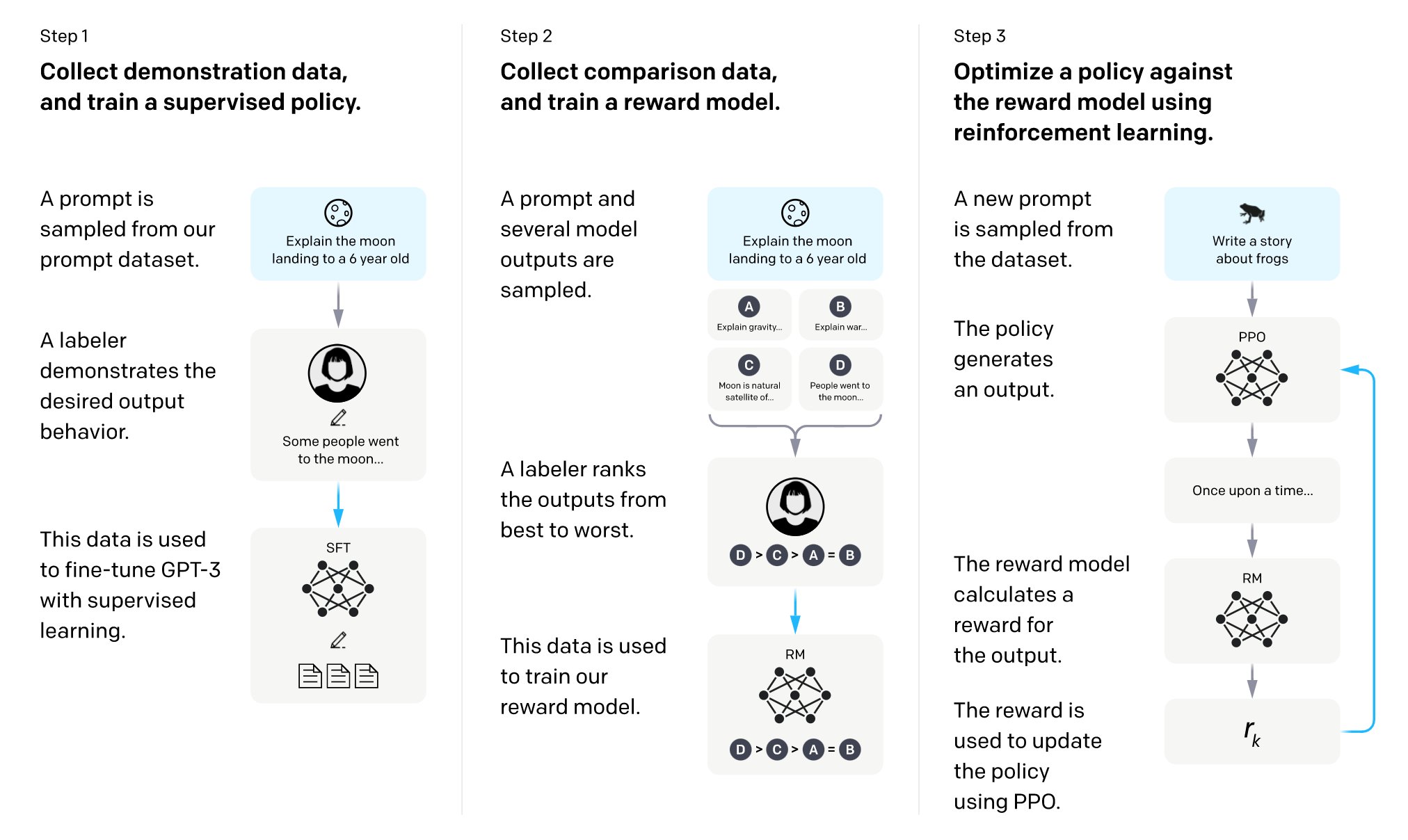
Q: How does this differ from publicly available "Instruction Tuning" (IT)?
A: Proprietary Alignment is actually 3 separate components:
1⃣ Instruction tuning
2⃣ ➕ Open-ended generation/creative prompts
3⃣ ➕ Human feedback
1/

Component 1⃣:
Instruction Tuning, in its simplest form, teaches the model to follow/answer instructions, instead of generating plausible continuations.
E.g. see @GoogleAI's Flan Collection: arxiv.org/abs/2301.13688
2/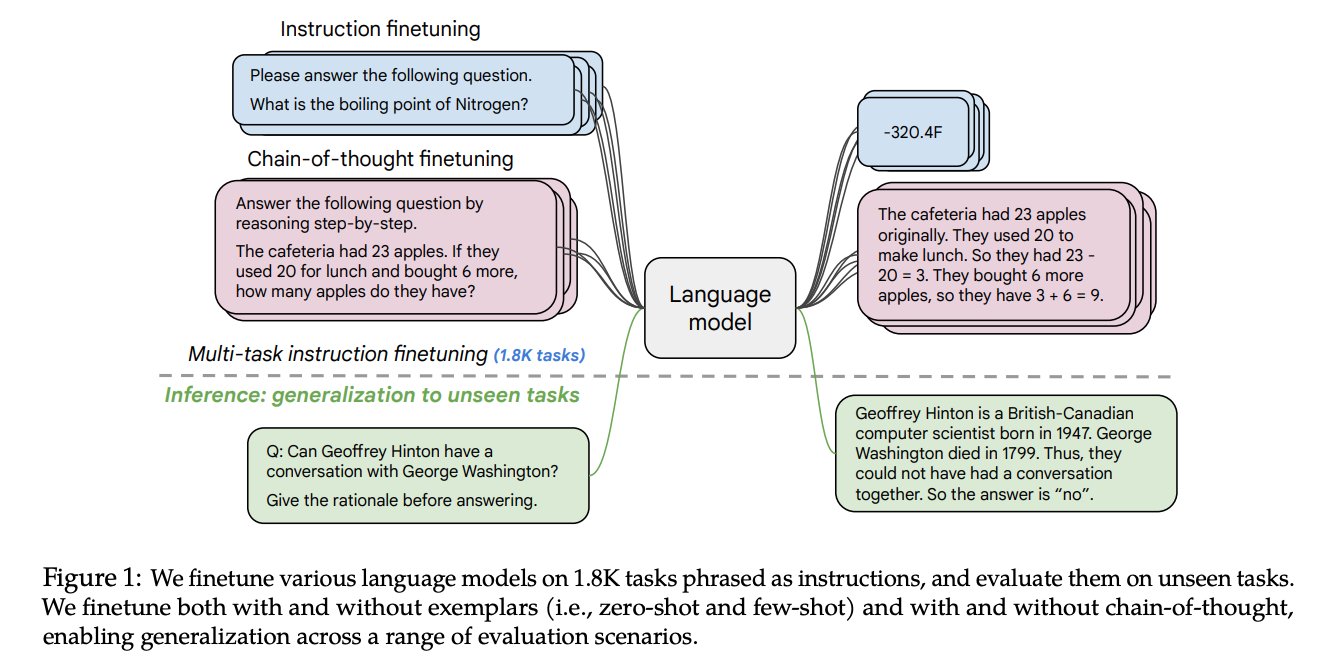
Instruction Tuning, in its simplest form, teaches the model to follow/answer instructions, instead of generating plausible continuations.
E.g. see @GoogleAI's Flan Collection: arxiv.org/abs/2301.13688
2/

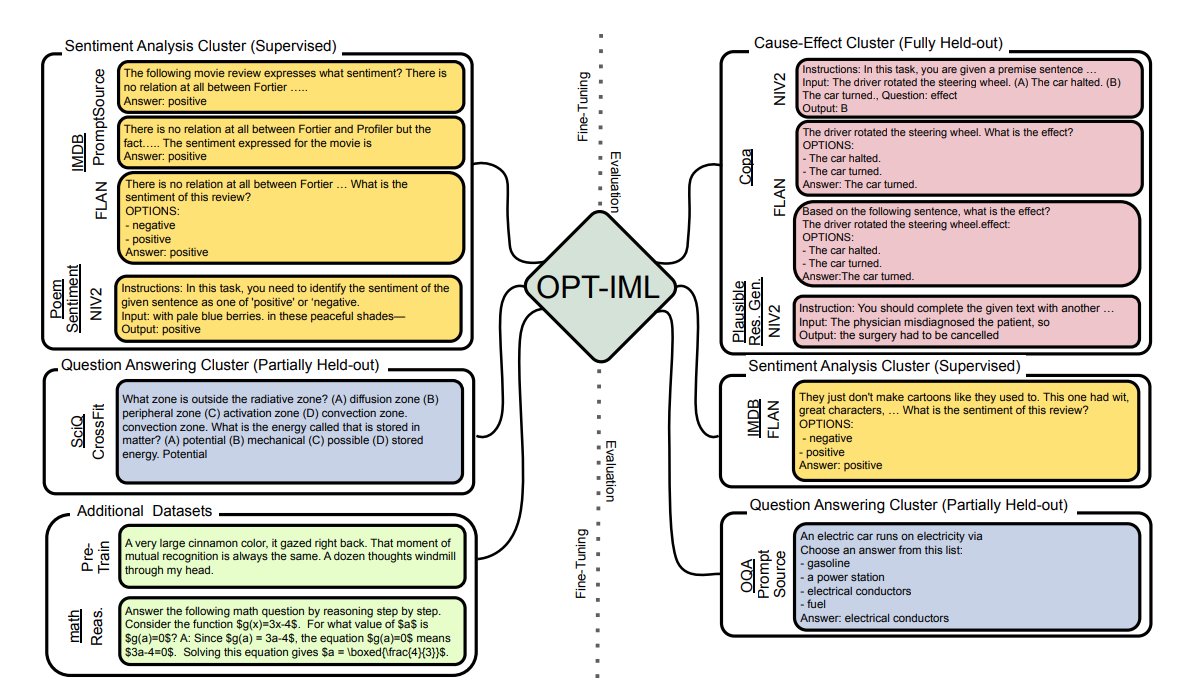
Instruction Tuning public collections are made of 95%+:
➡️ academic,
➡️ short-answer,
➡️ traditional,
NLP tasks. This is a limitation.
3/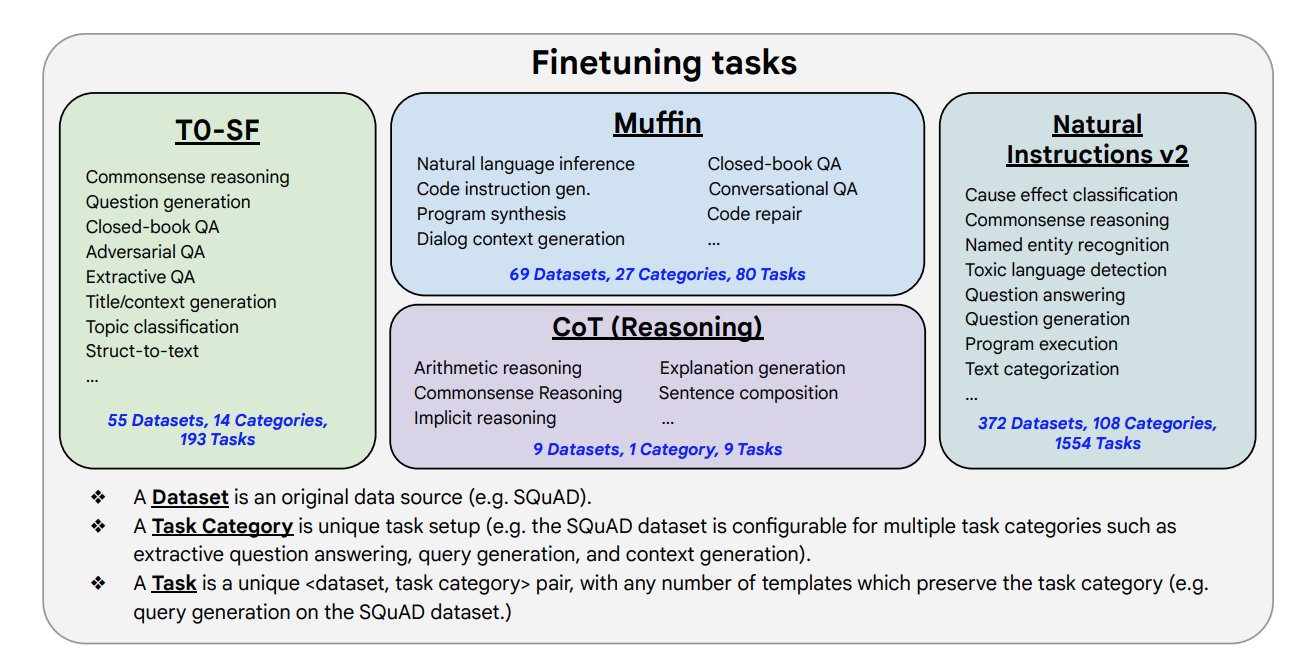
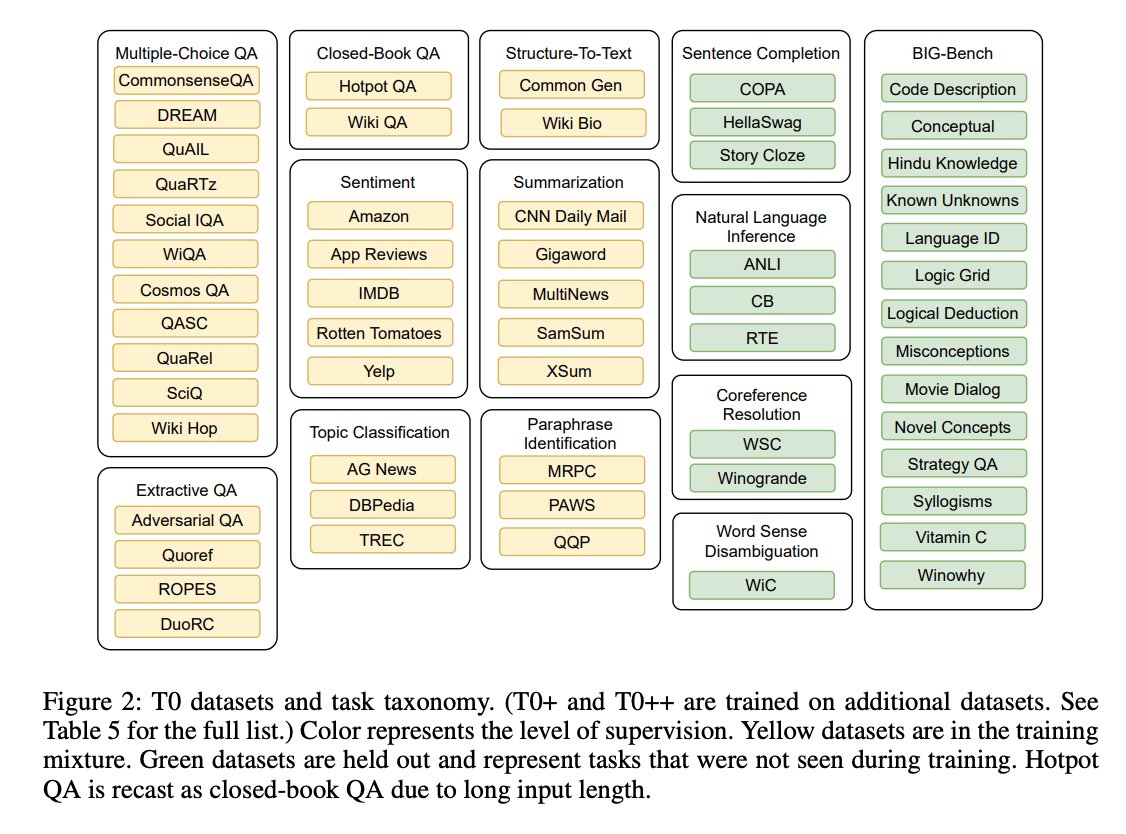
➡️ academic,
➡️ short-answer,
➡️ traditional,
NLP tasks. This is a limitation.
3/


Component 2⃣:
The InstructGPT blog confirms @OpenAI uses the public-sourced Playground inputs for training.
🌟 These are inevitably MUCH more diverse, challenging, and creative 🎨 than traditional NLP 🌟
openai.com/blog/instruction-following/ by @ryan_t_lowe, @janleike
4/
The InstructGPT blog confirms @OpenAI uses the public-sourced Playground inputs for training.
🌟 These are inevitably MUCH more diverse, challenging, and creative 🎨 than traditional NLP 🌟
openai.com/blog/instruction-following/ by @ryan_t_lowe, @janleike
4/
Because...
1. Traditional NLP is skewed to tasks w/ *automatic* eval metrics (mostly short text answers)
2. Human users try to push GPT-3s limits
➡️ Creative/long generation inputs (e.g. essay/poem writing, explanation) teach models new skills
5/
1. Traditional NLP is skewed to tasks w/ *automatic* eval metrics (mostly short text answers)
2. Human users try to push GPT-3s limits
➡️ Creative/long generation inputs (e.g. essay/poem writing, explanation) teach models new skills
5/
Component 3⃣:
@OpenAI guides models (indirectly) w/ human preferences over possible generations, using Reinforcement Learning from Human Feedback (RLHF).
GPT-3++'s results are often often credited primarily to this component -- but is that fair/true?
6/
@OpenAI guides models (indirectly) w/ human preferences over possible generations, using Reinforcement Learning from Human Feedback (RLHF).
GPT-3++'s results are often often credited primarily to this component -- but is that fair/true?
6/
Firstly, researchers are now asking: do we need RL or just the human feedback?
7/
7/
🌟 Take-aways 🌟
So how much does any component matter?
Is human feedback needed at all if we had more public diverse/open-ended/creative input-output pairs?
E.g. Bias/toxicity goals are improved significantly even w/o human values (just IT):
9/
So how much does any component matter?
Is human feedback needed at all if we had more public diverse/open-ended/creative input-output pairs?
E.g. Bias/toxicity goals are improved significantly even w/o human values (just IT):
9/
➡️ Answering these questions will prioritize future work for the field.
10/
10/
🌟 Take-aways 🌟
So much emphasis has been put on the results of Alignment and RLHF, but effectively training the next generation of models will require measuring each component of Alignment.
11/
So much emphasis has been put on the results of Alignment and RLHF, but effectively training the next generation of models will require measuring each component of Alignment.
11/
🌟 Disclaimer 🌟
I don't work at OpenAI, and ChatGPT remains unpublished/documented, so this is based mostly off of InstructGPT's paper (arxiv.org/abs/2203.02155, @longouyang).
Speculatively, I would bet ChatGPT benefits from new techniques, e.g. interactive/dialog tuning.
12/
I don't work at OpenAI, and ChatGPT remains unpublished/documented, so this is based mostly off of InstructGPT's paper (arxiv.org/abs/2203.02155, @longouyang).
Speculatively, I would bet ChatGPT benefits from new techniques, e.g. interactive/dialog tuning.
12/
There are also new Human Feedback datasets now publicly available:
➡️ Anthropic's HH-RLHF: huggingface.co/datasets/Anthropic/hh-rlhf
➡️@ethayarajh cleverly mined 385k Reddit comments (Stanford Human Preferences:
)
13/
➡️ Anthropic's HH-RLHF: huggingface.co/datasets/Anthropic/hh-rlhf
➡️@ethayarajh cleverly mined 385k Reddit comments (Stanford Human Preferences:
)
13/
There are also new exciting works circumventing Human Feedback and Creative prompt collection:
ConstitutionalAI: www.anthropic.com/constitutional.pdf (@AnthropicAI)
Self-Instruct: arxiv.org/abs/2212.10560 (@yizhongwyz)
Unnatural Instructions: arxiv.org/abs/2212.09689 (@OHonovich)
14/
ConstitutionalAI: www.anthropic.com/constitutional.pdf (@AnthropicAI)
Self-Instruct: arxiv.org/abs/2212.10560 (@yizhongwyz)
Unnatural Instructions: arxiv.org/abs/2212.09689 (@OHonovich)
14/
Why is this important?
Scaling these new works offer an opportunity for academia and public research to catch up to proprietary models.
15/
Scaling these new works offer an opportunity for academia and public research to catch up to proprietary models.
15/
The challenge?
Commercial and public LLM research's relationship is asymmetric, or one-way: corporations can benefit from academic findings, but less commonly in reverse.
16/
Commercial and public LLM research's relationship is asymmetric, or one-way: corporations can benefit from academic findings, but less commonly in reverse.
16/
Thank you for reading this far. If you have feedback or want to chat, shoot me a DM!
17/17
17/17
Mentions
See All
Stefania Druga @Stefania_druga
·
Feb 27, 2023
Great thread from Shayne as always