Thread by Jonathan Frankle
- Tweet
- May 5, 2023
- #DataScience #Naturallanguageprocessing
Thread
MPT is here! Check out our shiny new LLMs, open-source w/commercial license. The base MPT-7B model is 7B params trained on 1T tokens and reaches LLaMA-7B quality. We also created Instruct (commercial), Chat, and (my favorite) StoryWriter-65k+ variants. 🧵 www.mosaicml.com/blog/mpt-7b
The weights are available on HuggingFace, you can play with the Instruct and Chat variants on Spaces, and the code is available in our MosaicML LLM Foundry. (StoryTeller needs bigger GPUs, so you'll have to download that to use it.) huggingface.co/spaces/mosaicml/mpt-7b-instruct
LLM quality is v difficult to evaluate. For quantitative eval on academic in-context learning tasks, see the attached table. We downloaded checkpoints and re-evaled everything in the same setup. I argue we surpass all open-source < 30B models and go hoof-to-hoof with LLaMA-7B. 
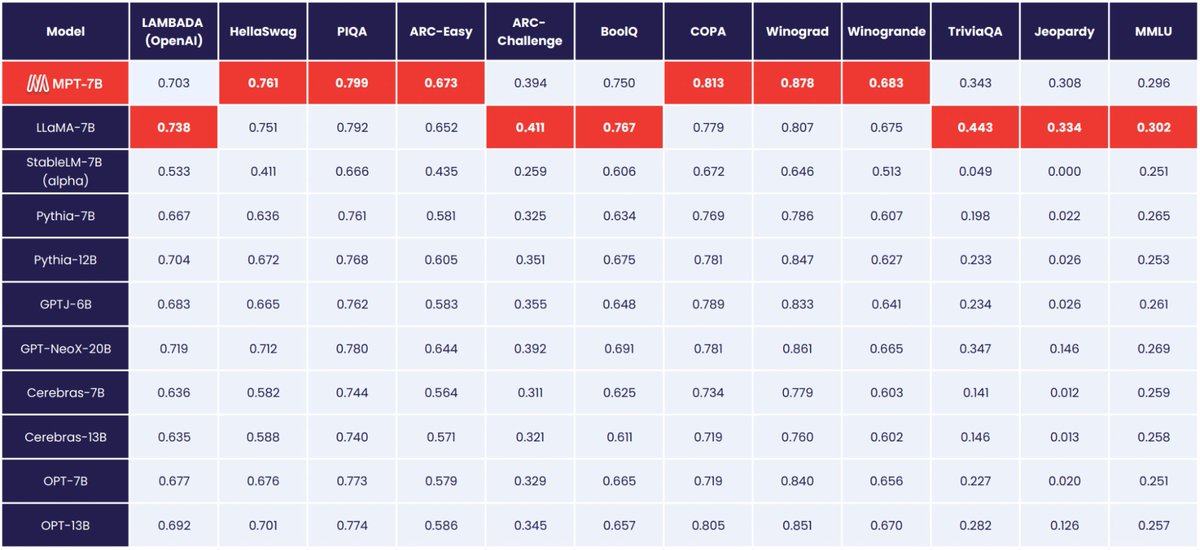
Among commercially-usable models (which LLaMA isn't), I don't think it's really a contest. Of course, quantitative evals don't capture the real-world quality of generation. For vibe-checks, play with the models on HuggingFace and decide for yourself. huggingface.co/spaces/mosaicml/mpt-7b-chat
Technical details: The base model was trained on a @MosaicML-curated mix of 1T tokens of text+code. We trained for 9.5 days on 440 A100s (cost: $200k). We worked extensively on the data mix for this model. (If you've seen my Twitter lately, you know this was my passion project.) 

We used the same tools as our customers. Composer + StreamingDataset made setting things up simple. We created our own LLM codebase and Transformer variant to maximize efficiency+ease. It uses @PyTorch FSDP (no pipeline/tensor parallel) and gets 40-60% MFU github.com/mosaicml/llm-foundry
How did training go? Zero human intervention needed. None. Nada. Our arch+optimization changes eliminated all loss spikes. The @MosaicML platform (our proprietary training software available to customers) caught and recovered from four hw failures. Please enjoy our empty logbook. 



This is the same setup our customers use. Our friends at @Replit trained their 3B param code model with all of these tools. That project went from dream to completion in ten days, and the main training run took three days. Work with us and do the same! www.mosaicml.com/platform
To show you what you can do with these models (and our tools), we finetuned to create three variants of MPT-7B. First, MPT-7B-Instruct, fine-tuned on @databricks Dolly and Anthropic HHRLHF. It's a commercially usable, (imo) really nice instruction-follower huggingface.co/spaces/mosaicml/mpt-7b-instruct
Second, MPT-7B-Chat, fine-tuned on all of the recent chat datasets (Alpaca, Vicuna, etc.). It isn't licensed for commercial use due to the nature of those datasets, but it provides a nice demonstration of what it's possible to build on this foundation. huggingface.co/spaces/mosaicml/mpt-7b-chat
Third - my personal favorite - MPT-7B-StoryWriter-65k+. This model is fine-tuned on English language literature with a context length of 65k. How? We use ALiBi position encodings (@OfirPress), so the model can use any length and extrapolate longer (up to 84k in our testing). 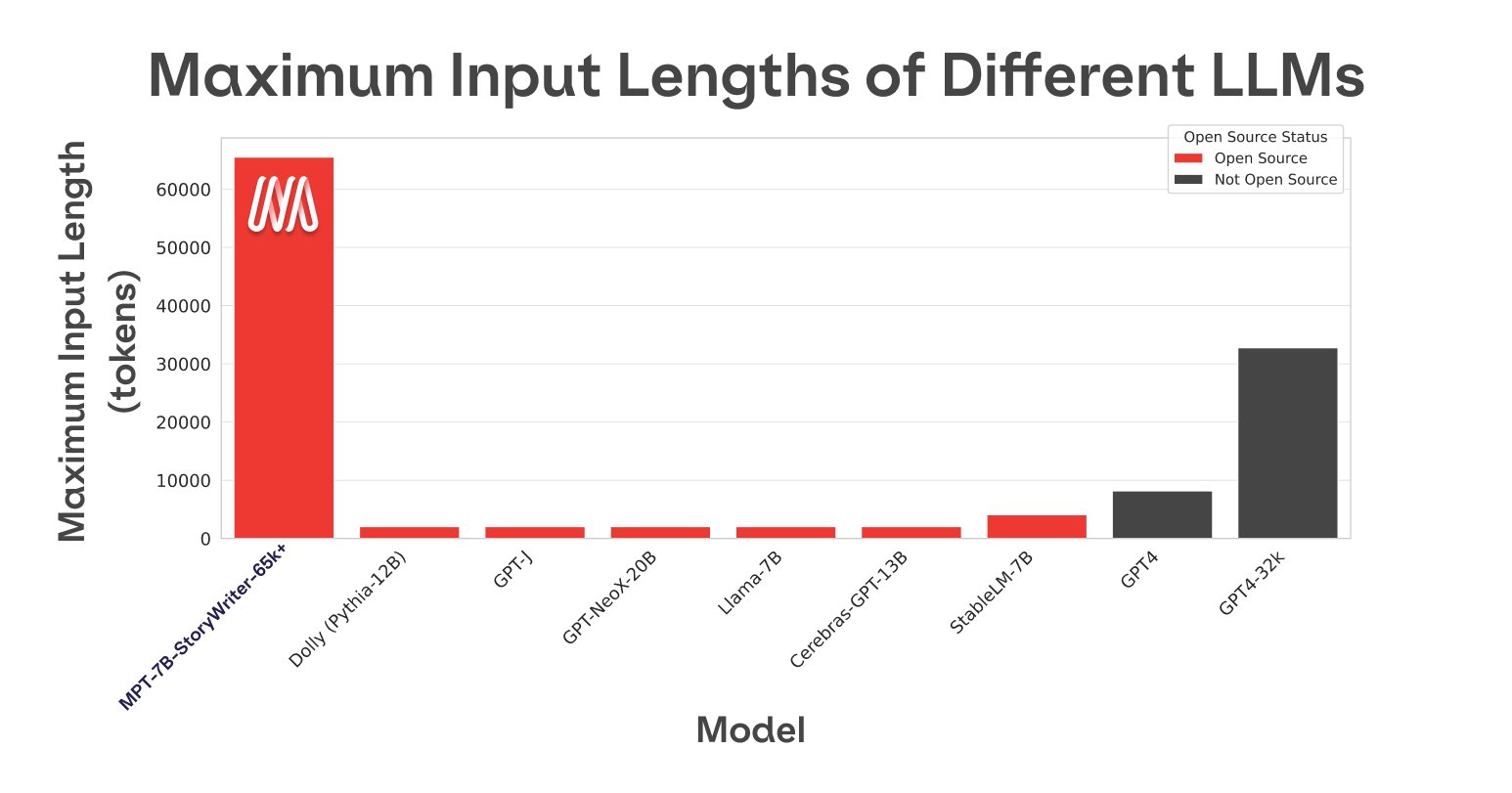



Why did we build this? (1) @MosaicML's business is to help enterprises to train custom, private versions of big, complicated models like LLMs. How do you know we can train a great LLM for you? Check out these ones! If you'd like to train your own with us: forms.mosaicml.com/demo
(2) I truly believe in openness. The rapid scientific progress in recent years in deep learning is a result of openness: sharing ideas, data, artifacts. The big labs may have stopped sharing, but we at @MosaicML believe in the open community. We'll continue to share + support it.
This project is the culmination of two years of work at MosaicML to make deep learning efficient and accessible for everyone. From great infrastructure to great tools to great science, we've been laying the groundwork to train models like this over and over and over again.
Expect much more where this came from. The MPT-7B family and Stable Diffusion 2.0 for < $50k (if you can remember back to last week) are warmups for what we have coming next and what we can do for you on your data. www.mosaicml.com/blog/training-stable-diffusion-from-scratch-part-2
There are far too many people to recognize here, but a big shoutout to @abhi_venigalla, who spearheaded this project, and to the many many researchers and engineers at @MosaicML whose work made this release possible. And to the friends we made along the way at @allen_ai.
Finally, thank you to the open-source community. We stand on the shoulders of giants like @AiEleuther, @Allen_AI, @metaai, @OfirPress, @tri_dao, @realDanFu, @nvidia, @GoogleAI, @huggingface, @PyTorch, @togethercompute. MPT is our gift to the community. Build on it and surpass it! 
