Thread by Pierluca D'Oro
- Tweet
- Feb 3, 2023
- #Deeplearning #DataScience
Thread
Our paper "Sample-Efficient Reinforcement Learning by Breaking the Replay Ratio Barrier" has been accepted to ICLR as top 5%!
We show that lots of updates and resets lead to great sample efficiency.
Come for the scaling, stay for the insights.
openreview.net/forum?id=OpC-9aBBVJe
1/N🧵
We show that lots of updates and resets lead to great sample efficiency.
Come for the scaling, stay for the insights.
openreview.net/forum?id=OpC-9aBBVJe
1/N🧵

Last year, we investigated "the primacy bias" (arxiv.org/abs/2205.07802), due to which deep RL agents are unable to leverage the data they acquire during training.
Once the agent is able to better leverage its data, what is the limit of the knowledge it can gain from them?
2/N
Once the agent is able to better leverage its data, what is the limit of the knowledge it can gain from them?
2/N
To get closer to this limit, we employ a natural strategy: increasing the number of updates in between interactions with the environment.
We show that algorithm modifications based on resets allow to "break the replay ratio barrier", transforming compute into performance.
3/N
We show that algorithm modifications based on resets allow to "break the replay ratio barrier", transforming compute into performance.
3/N
In continuous control, it amounts to a reset strategy tight to the number of updates. The more updates, the more resets, to always allow the agent to fully leverage its data.
In discrete control, we study the effect of scalability of a series of design decisions.
4/N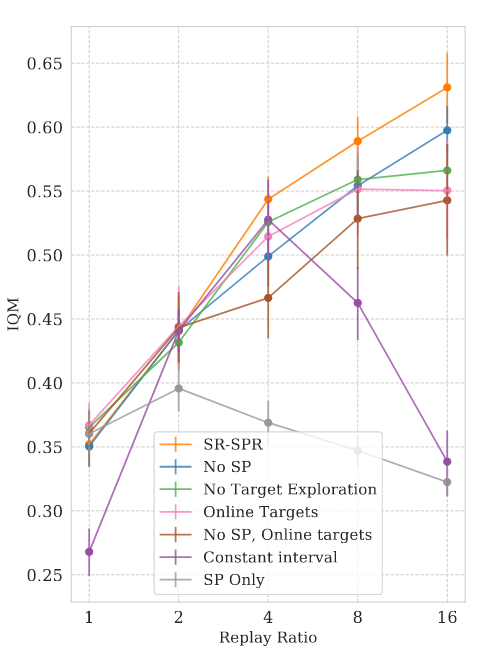
In discrete control, we study the effect of scalability of a series of design decisions.
4/N

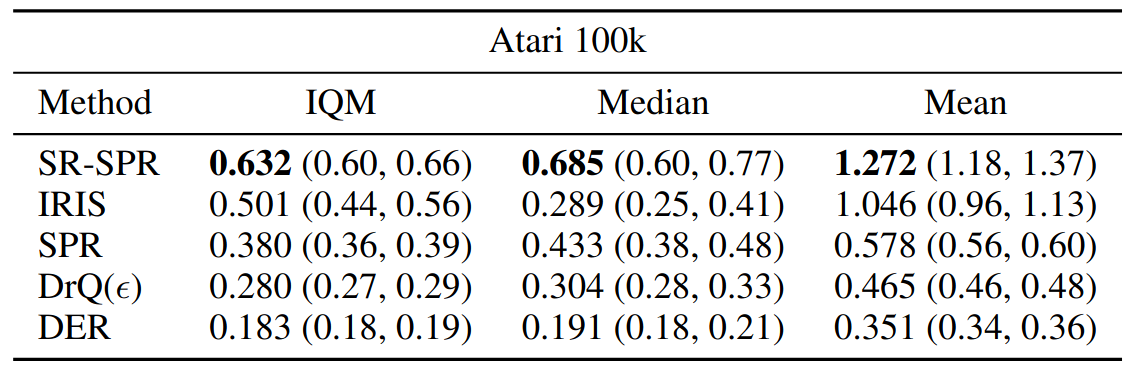
The resulting algorithms, Scaled-by-Resetting SAC and SPR obtain SOTA model-free performance, with very simple implementations. They achieve this by leveraging 4x more updates than similar methods.
But we didn't stop there.
5/N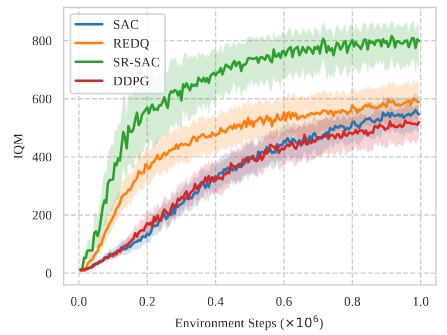
But we didn't stop there.
5/N


We wanted to understand why this approach works. Doing 100 updates in between environment steps is close to a hybrid setting between offline and online RL.
We study the interaction between offline and online training: you can do part of the updates offline, but not too much.
6/N
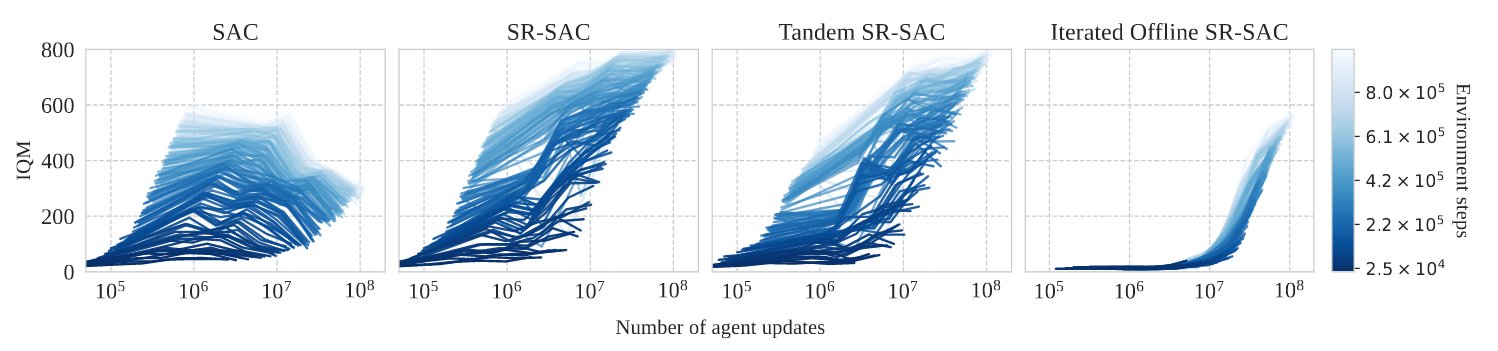
We study the interaction between offline and online training: you can do part of the updates offline, but not too much.
6/N


This shows that data collected online, even just a tiny amount, matters for scalability (echoing tandem arxiv.org/abs/2110.14020).
Oh, and we use another empirical phenomenon, the policy churn, to explain SR-SPR scalability.
Please keep working on empirical discoveries!
7/N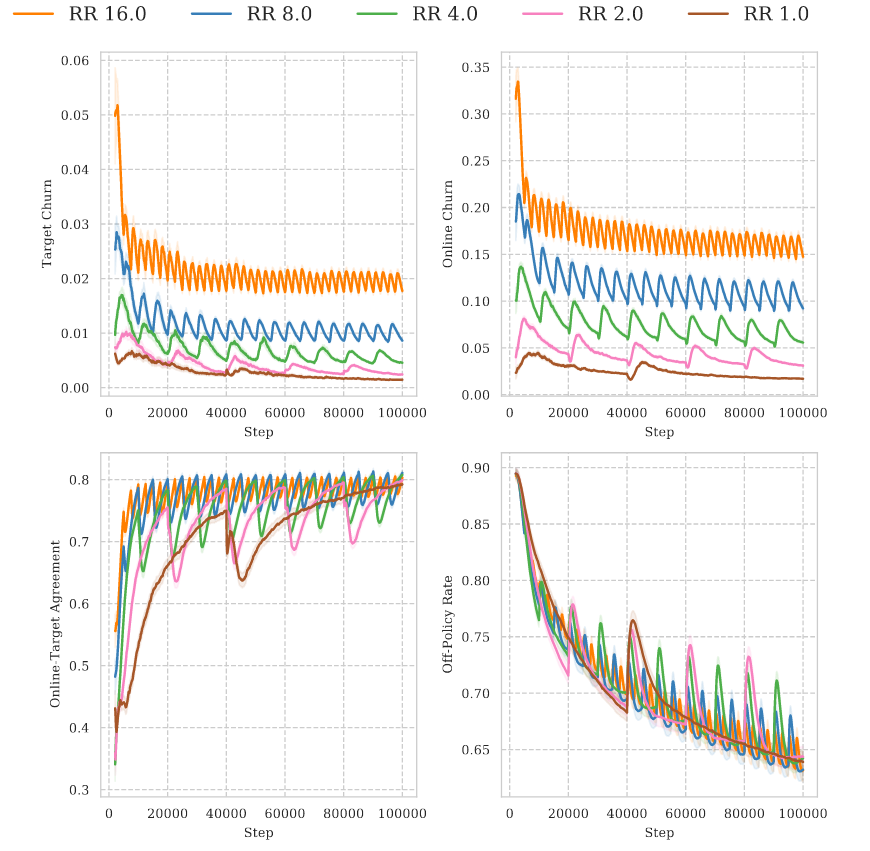
Oh, and we use another empirical phenomenon, the policy churn, to explain SR-SPR scalability.
Please keep working on empirical discoveries!
7/N

Lastly, with great power comes great responsibility. Doing a lot of agent updates could be expensive.
Fortunately, varying the amount of updates gives you an easy knob for varying the amount of computations. Depending on whether data or compute is cheaper, just vary that.
8/N
Fortunately, varying the amount of updates gives you an easy knob for varying the amount of computations. Depending on whether data or compute is cheaper, just vary that.
8/N

This work has been the result of an outside-of-the-box collaboration with @max_a_schwarzer, who co-led this work with me, @nikishin_evg, @pierrelux, @marcgbellemare, and @AaronCourville.
Hear me out: buy a winter jacket and come to @Mila_Quebec to do deep RL research.
9/9
Hear me out: buy a winter jacket and come to @Mila_Quebec to do deep RL research.
9/9