Thread
This graph from the GPT-4 tech report is a much bigger deal than most people seem to have realised.
I think it allows us to predict with reasonably high confidence that the problem of LLM's making things will be quite easy to solve.
Here's why: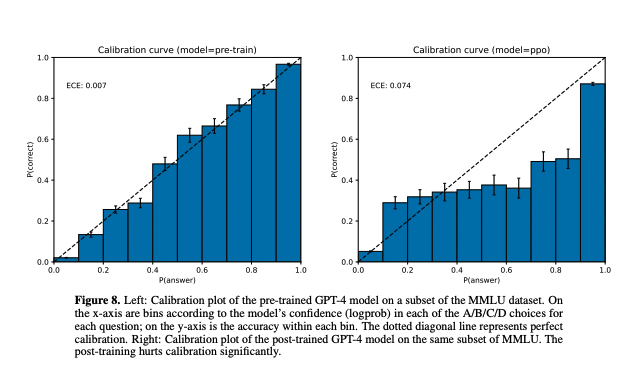
I think it allows us to predict with reasonably high confidence that the problem of LLM's making things will be quite easy to solve.
Here's why:

The graph shows the GPT-4's "calibration" before and after RLHF. A well-calibrated model can accurately say how confident it is.
The researchers compare GPT-4's probability for the answer to the fraction of the time it's correct.
The researchers compare GPT-4's probability for the answer to the fraction of the time it's correct.
A perfectly calibrated model will get 10% of the answers correct when it has 10% confidence, 20% at 20% confidence etc. So on the graph above, perfect calibration corresponds to a straight line.
GPT-4 is very well-calibrated! It knows what it doesn't know!
GPT-4 is very well-calibrated! It knows what it doesn't know!
After the model is RLHF fine-tuned (made "safe"), the calibration is bad but generally under-confident.
Why is this a big deal?
Why is this a big deal?
Since GPT-4 has well-calibrated confidence we can use its confidence estimates to decide when to trust the model.
If the calibration is good, then we don't need to worry about models making things up.
If the calibration is good, then we don't need to worry about models making things up.
Just ask the model for its confidence and ignore low-confidence answers.